














 TechMagic Academy
TechMagic AcademyAWS Data Pipeline: 4 Reasons To Use It In Your App
Last updated:16 March 2026


Over the past decade, data has shifted from a byproduct to a core business asset. But having more data doesn’t automatically mean better decisions. In reality, most companies struggle with scattered, low-quality, or underused data, and that’s where the problem starts.
A recent research by Seagate shows that up to 68% of enterprise data goes unused. And it’s not because it lacks value, but because organizations struggle to move, process, and organize it effectively. The main issue is structure. Without a clear way to move, process, and organize data, even the most valuable datasets quickly become noise.
This is exactly where data pipeline AWS solutions, including AWS data pipelines, come into play. If you’ve ever asked yourself what is AWS Data Pipeline and how it fits into a real system, the short answer is simple: it helps you move, transform, and prepare data so it can actually be used.
In this article, we’ll break down how data pipeline in AWS works, where it fits, and when it makes sense to use it in your application.
Key Takeaways
- AWS data pipeline helps move, transform, and schedule data across systems.
- It works as an orchestration layer for automated data workflows.
- AWS data pipelines reduce manual work by automating extraction, transformation, and loading.
- A well-designed data pipeline in AWS supports scalability as data volumes grow.
- It helps improve data accuracy and prepare information for analytics and reporting.
- A practical AWS data pipeline example shows how to build reliable scheduled workflows for production use.
What Is AWS Data Pipeline?

AWS Data Pipeline is a managed service designed to move and process data between different systems in a structured way. Amazon Data Pipeline acts as an orchestration layer that helps you define how data should be collected, transformed, and delivered across your environment.
A data pipeline in AWS is not limited to transferring data from point A to point B. It also handles transformation along the way. As data flows through the pipeline, it can be cleaned, aggregated, or enriched so it becomes usable at its destination. This is why AWS data pipelines are often used to support ELT workflows, where raw data is first loaded and then processed using services like Amazon EMR or other AWS resources.
From an architectural perspective, this fits into a broader AWS data pipeline architecture where pipelines define data driven workflows across storage, compute, and analytics services. Instead of building everything from scratch, teams can create pipelines using predefined templates and integrate them with the wider AWS ecosystem.
If you are following an AWS data pipeline tutorial or implementing your first setup, the key concept to remember is this: the pipeline controls how data moves, when tasks run, and how processing happens. It becomes the backbone of your AWS cloud pipeline, especially when you need reliable scheduling, automation, and moving data between systems at scale.
Why Do You Need a Data Pipeline?
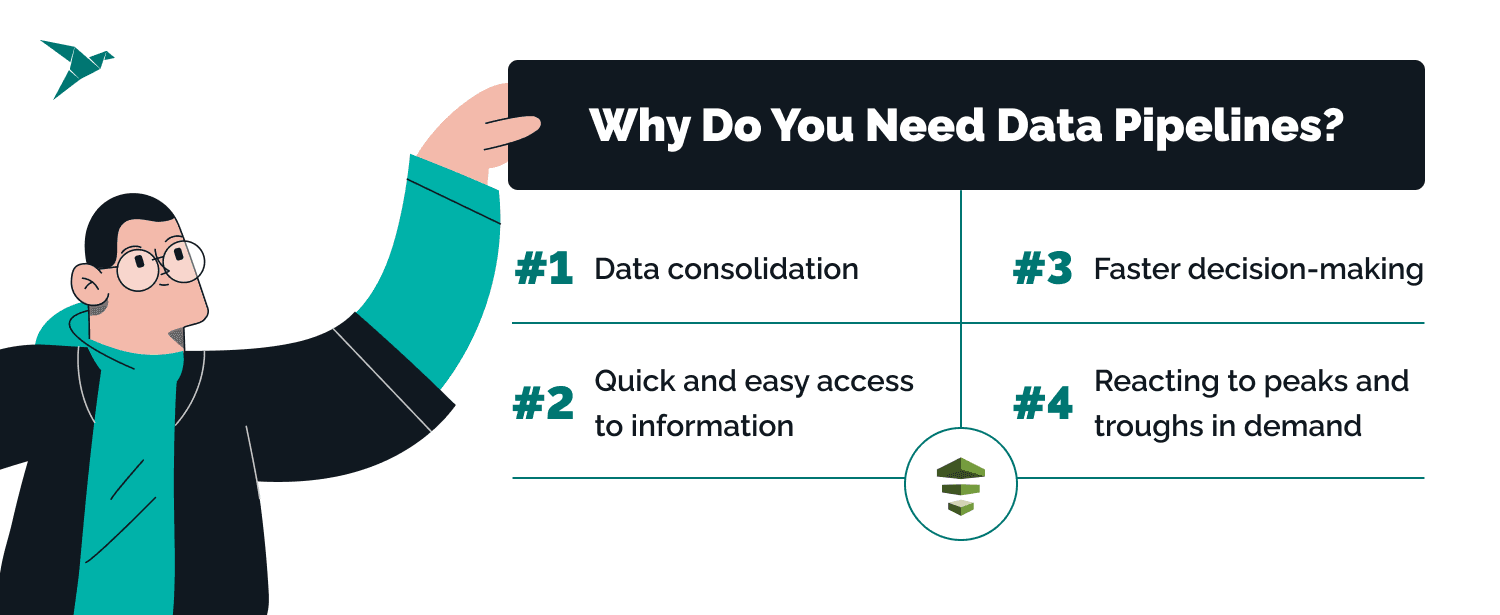
There are plenty of tools that promise business impact, and it’s fair to question where a data pipeline fits in. But once data volume and complexity grow, the need becomes obvious. Without a structured way to extract data, process large data volumes, and store data reliably, even the best analytics tools won’t deliver value.
Every business will have its own industry-specific answers to that question, but here are four broad-brush use cases of AWS data pipelines, defined from our experience delivering data engineering services.
Data consolidation
Most businesses use multiple tools that generate overlapping data. A data pipeline AWS setup helps bring data from cloud apps and on premises data sources into one place, reducing silos and improving data accuracy.
Quick access to usable information
Raw data is rarely ready for analysis. An Amazon data pipeline can extract data, transform it, and prepare it for a SQL database, dashboard, or query API, so data analysts can work with insights instead of cleaning files manually.
Faster decision-making
When data is processed automatically, teams do not have to wait for manual reports. A data pipeline in AWS can run tasks on schedule and keep business data ready for reporting, forecasting, and daily operations.
Better handling of growth
As data volumes grow, manual processes break down quickly. AWS data pipelines help companies process large data volumes more reliably and adapt to changes in demand without constant rework.

What Are the Components of AWS Data Pipeline?
AWS Data Pipeline consists of several key components that work together to enable the efficient movement and transformation of data for intelligent business insights. Let's explore each of these components in detail:
- Data pipelines are the core building blocks of AWS Data Pipeline. They define the flow and processing of data from various sources to destination locations such as organizations' data centers. A pipeline consists of a series of activities and resources that manipulate a million files of data as it moves through the pipeline.
- Data nodes represent the data source or destinations within the AWS data pipelines. They define data movement and where it should be stored. It supports various types of data nodes, including:
- SqlDataNode
- DynamoDBDataNode
- RedshiftDataNode
- S3DataNode
- Task runner is responsible for executing the activities defined in the pipeline. It runs on a compute resource and performs the necessary actions, such as data extraction, transformation, and loading. The task runner ensures the smooth execution and error handling of the pipeline activities according to the defined schedule and dependencies.
- Activities are the individual tasks performed within pipeline. Each activity carries out a specific operation on the data, such as data transformation, aggregation, or filtering. AWS Data Pipeline provides various built-in activities, such as ShellCommandActivity, HiveActivity, EMRActivity, and more. Additionally, you can create custom activities using its activity templates.
- Pipeline Log files generate log files that provide detailed information about the execution and status of the pipeline in a moment. These log files capture important metrics, error messages, and diagnostic data, which can be valuable for troubleshooting and monitoring the pipeline's performance.
How Does AWS Data Pipeline Work?
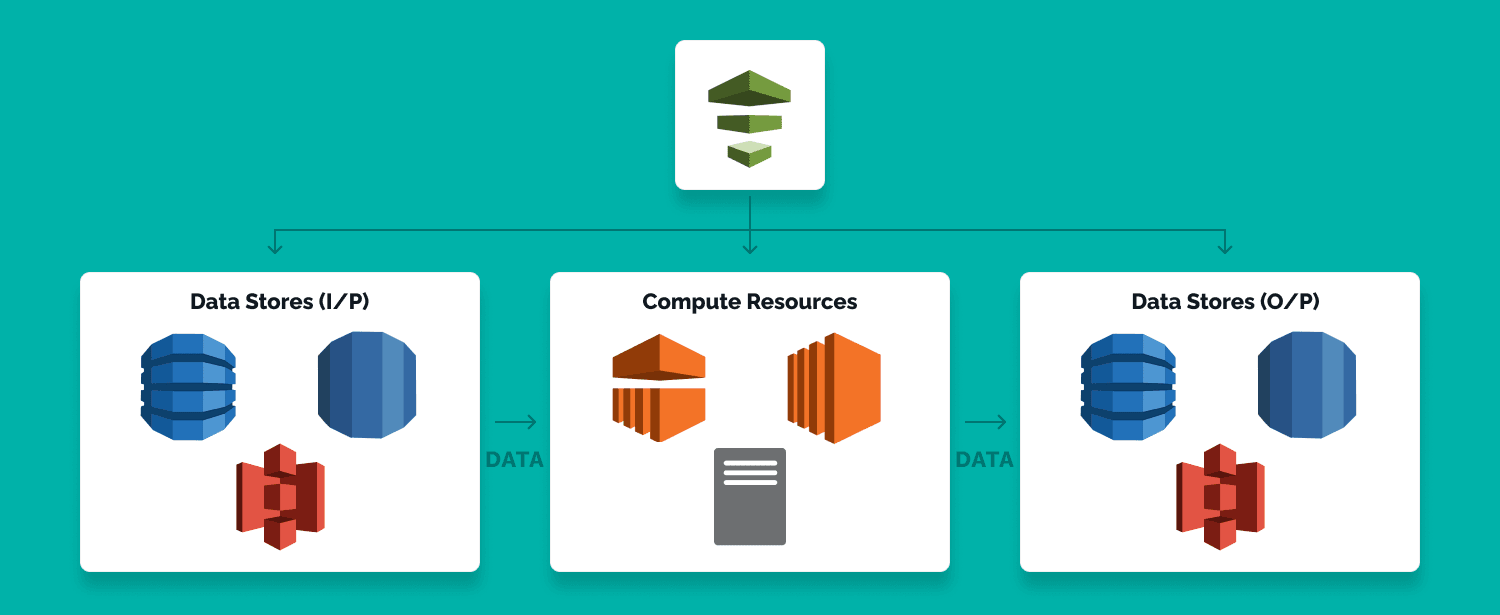
AWS data pipeline works on a schedule. Data is pulled from one or more sources at specified intervals, processed according to the pipeline logic, and moved to a target system. Those sources can include databases, APIs, CRM platforms, IoT systems, and other tools across AWS compute and external environments.
The pipeline then transforms the data where needed and sends it to a destination such as Amazon S3, a data warehouse, or a SQL database. This can include tasks like loading AWS log data, cleaning records, or running a table query. The main value is simple: it automates recurring processing so users can work with ready-to-use data instead of preparing it manually every time.
an E-commerce analytics app using JS and Serverless on AWS
Why Does AWS Stand Out?
AWS is not the only option for pipeline orchestration, but it stands out because it combines scheduling, processing, and integration inside one ecosystem. For companies already using AWS systems and other AWS services, that makes adoption much easier.
Simple interface and access options
AWS Data Pipeline can be managed through the AWS Management Console, which gives users a clear web interface for building and monitoring pipelines. It also supports the AWS command line interface, the AWS CLI, the AWS SDK, and a language specific API, which is useful for teams that want automation instead of manual setup.
Broad connectivity
It can move data between multiple AWS services and external systems, including common on-premise data sources. That flexibility matters when pipelines need to connect cloud workloads with existing business systems.
Scheduling and dependency handling
AWS Data Pipeline supports chained execution, so tasks can run based on the success or failure of previous steps. This is useful when workflows depend on resource availability, upstream results, or strict execution order.
Flexible processing and pricing
The service supports several transformation approaches, including SQL, EMR, and custom code. It also uses a usage-based pricing model, which helps keep costs under control for periodic or scheduled workloads.

What Are the Advantages of Working with AWS Data Pipeline?

For the right use case, AWS data pipeline gives you enough control to create pipelines, automate recurring jobs, and keep data moving without building everything from scratch. Before you dive in and book an appointment with TechMagic’s AWS Migration Consulting team, let's discover the benefits.
Low cost
AWS Pipeline is relatively inexpensive for periodic workloads. You pay for the service and for the compute and AWS resources it uses, which makes it easier to control costs when pipelines are not running all the time.
Flexible execution
It can support running SQL queries directly on databases, trigger EMR jobs, and run custom processing logic. That makes it useful when your data pipeline work includes batch transformation, scheduled imports, data analysis, or moving data between storage, compute, and analytics services.
Easy to work with
The web service can be configured through a web based interface in the console, so you do not have to build every workflow entirely in code. Prebuilt options and template libraries help speed up setup, especially for common pipeline patterns.
Scales with workload
AWS Data Pipeline can handle small recurring jobs as well as larger scheduled workloads. Whether you need to process a few files or much larger datasets, it can support that growth without redesigning the whole flow.
Good visibility
The service gives you execution history, status tracking, and logs that help you monitor pipeline behavior. That matters when you need to troubleshoot failures, verify schedules, or simply leave logging enabled for operational visibility. A US nationwide survey by Morning Consult found that people have more trust in Amazon than in the government or police. That trust extends into the business community. Users feel confident using AWS Data Pipeline with services like Amazon EC2.
Are There Any Downsides to AWS Data Pipeline?
AWS Data Pipeline is useful, but it is not the best fit for every scenario. Like many older AWS services, it works well in the right context, but it also has limitations that matter when you compare it with newer orchestration and integration tools.
Limited third-party integration
AWS Data Pipeline works best inside the AWS ecosystem. It connects well with native AWS systems and other AWS services, but support for external platforms is more limited than in many modern data integration tools. That can be a drawback if your pipeline needs to connect many non-AWS systems or SaaS tools.
It can get complicated
Once you start working with multiple data sources, schedules, and compute environments, the setup can become harder to manage. Things like pipeline configuration, connection details, task dependencies, and hybrid infrastructure add complexity quickly, especially with complex data processing workloads. For experienced AWS users this is manageable, but for newcomers the learning curve is real.
What Are the Alternatives to AWS Data Pipeline?

Common alternatives include AWS Glue, Hevo, Apache Airflow, and Fivetran. AWS Glue is a strong option for serverless ETL, Airflow is useful when you need more control over workflow and business logic, and tools like Hevo or Fivetran are often chosen for simpler managed integrations. If your main goal is moving and preparing data for analytics or a data lake, the best choice depends on how much control and customization you need.
By the way, our AWS Serverless Consulting team is on hand to answer all questions!
Summing Up and How We Can Help
AWS Data Pipeline is a solid option for scheduling, moving, and processing data inside the AWS ecosystem. It works best for predictable workflows where you need control over execution and timing, but not a fully serverless setup.
If you’re not sure whether it’s the right fit or want to design a more scalable data architecture, TechMagic can help you choose and implement the best approach for your case.

FAQ
AWS Data Pipeline is a service for moving and processing data between storage, compute, and analytics systems.
It is mainly used by data engineers and technical teams that need scheduled data movement and processing. The output can then support reporting and analysis across the business.
Common alternatives include AWS Glue, Apache Airflow, Hevo, and Fivetran. If you need a more modern AWS Data Pipeline serverless option, AWS Glue is usually the first one to compare.
AWS Glue is a serverless ETL service built on Apache Spark, while datapipe AWS is more focused on orchestration and scheduled workflow execution. A typical AWS Data Pipeline example is a scheduled job with fixed pipeline schedules, clear inter task dependencies, and other critical components of a recurring workflow.