














 TechMagic Academy
TechMagic AcademyAWS Databases User Guides: How to Choose the Right One
Last updated:21 October 2022


Cloud consumers now have more database alternatives for recording, storing, sorting, and analyzing than ever, and cloud service provider offers more possibilities than AWS.
The data a company gathers on its clients, operations, goods, and services is critical to its effective day-to-day operations to offer excellent customer experiences, streamline operations, and make educated, proactive choices.
You can quickly design, scale, secure, and deploy big data products with the help of the breadth of data analytics resources offered by AWS. That held a 34% market share in the global cloud infrastructure market in the second quarter of 2022, outpacing the combined market shares of Microsoft Azure and Google Cloud.
We cover the functions, capabilities, and use cases of each AWS database to assist you in selecting one for your use case and project.
AWS Database
AWS Database Services is a collection of cloud-based databases provided by AWS.
AWS Database is a web service that provides scalable, durable, and easy-to-use database services that allow you to run your applications in the cloud. It offers automatic scaling, automatic backup and disaster recovery, and automatic database updates. The performance of an application is closely related to how well the underlying database operates for the application.
Importance of AWS Database
AWS provides many alternative database engines on its platform, each purpose-built and adaptable to various use cases. AWS assists organizations in moving away from a monolithic, one-size-fits-all strategy and choosing the proper database for the task, even if that means running many concurrently.
AWS Databases handles setup, availability, backups and recovery, hardware, administration overhead, licensing, and streamlined update processes. They are flexible, so you can experiment with multiple database systems and types without committing to hardware, license, or resources, pay for what you use, and cancel at any moment with no long-term obligations.
You can concentrate on your application development and company growth with AWS Database Services. For all hardware upgrades, security patches, and even software upgrades, AWS takes care at no cost!
Advantages of AWS databases
AWS provides reliable, scalable, and durable cloud-based databases with many features, including automatic snapshotting, durability, and high performance. They are easy to use and provide a modular architecture that makes adding new features and applications easy. AWS databases are:
Managed – easy to administer everything, from maintenance to hardware updates.
It allows your teams to spend less time on time-consuming database chores like server setup, patching, and backups. AWS fully managed database services enable you to focus on application development by providing continuous monitoring, self-healing storage, and automatic scalability.
Elastic – highly scalable without downtime
Begin small and expand as your applications development using relational databases that are 3-5X quicker than popular alternatives or non-relational databases with microsecond to sub-millisecond latency. You can match your storage and compute requirements quickly and frequently with no downtime.
Secure and reliable
Multi-region, multi-primary replication is supported, as is full data governance with different degrees of security, such as network isolation and end-to-end encryption. AWS databases provide the high availability, dependability, and security required for mission-critical enterprise applications.
AWS provides numerous databases, such as relational databases, non-relational databases, and so on. Let's talk about the different types of AWS Database Services.
AWS database solutions
AWS offers a comprehensive choice of fully managed, purpose-built database services to meet every application demand, including relational and non-relational databases. This database service allows you to use any number of Amazon Web Services (AWS) accounts to store your data. AWS provides fully managed database services, a data warehouse for analytics, and in-memory data storage for caching.
Modern application development is built on databases. Implementing a database and how data is organized will impact how effectively an application grows.
Let's discover each database service, beginning with Relational Database Services.
Types of databases on AWS
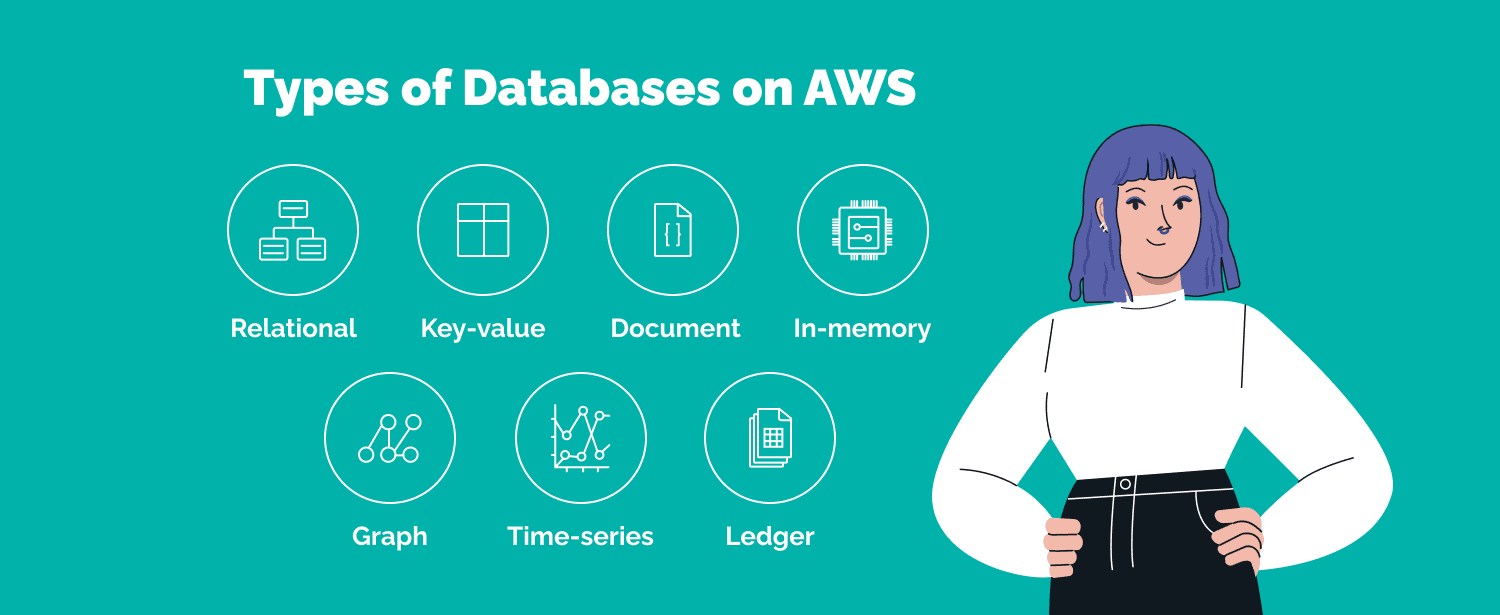
Relational or SQL databases
Relational databases, sometimes known as SQL databases because they employ the Structured Query Language to govern information storage and retrieval, have been commercially available and are designed to store data.
According to Trustradius, above 50% of enterprises operate AWS relational databases and just 14% of use small businesses.
Amazon Relational databases store data in tables with columns and rows, with each row representing a single record distinguished by a unique ID known as a key and each column having data about that record.
Each record often has a value for each data property in table columns, making constructing associations between data items simple. AWS performs basic database processes like provisioning, patching, backup, recovery, failure detection, and repair.
The fields that describe the data, the operations carried out on them, their relationships with one another, and most importantly, the rules that guarantee their integrity—all information in the database is always associated with other data and presented in a strictly and logically structured way.
Benefits of using relational databases:
- Faster data updates
- High level of security
- Easy access to data
- Data integrity and accuracy
Relational databases may be used for several purposes, including:
- CRM (customer relationship management) software
- Financial transaction data
- Enterprise resource planning applications (ERP)
AWS relational databases consist of Amazon Aurora, Amazon RDS and Amazon Redshift. Let’s get started with Amazon Aurora.
Amazon Aurora
Amazon Aurora is an AWS-specific relational database engine that is completely managed. Small adjustments to your source database make it compatible with MySQL and PostgreSQL.
Aurora provides such capabilities as:
- self-healing,
- fault tolerance,
- point-in-time recovery,
- and continuous backup
It denotes the database's usage of code, apps, and drivers. As with MySQL, you must write suitable queries to create tables and save data. You can interact between two or more Aurora databases using extensions and migrate your databases between Aurora and your local engine, which is a feature of this.
Database workloads may also be used to configure the Amazon Aurora RDBMS storage infrastructure. Amazon Aurora automatically expands storage in increments of 10 GB up to 64 TB. When you use benefits of Serverless, you are paid in Aurora capacity units (ACUs), which equal 2GB of memory plus compute and network resources.
Benefits of using Amazon Aurora:
- Great data availability
- Advanced surveillance, backup, and restoration
- Automatic redundancy
- Fast five times as quickly as a MySQL database
- Fault tolerance works without interruption if one or more components fail
- Capacity for duplication data across three Availability Zones.
Amazon Aurora use cases are:
- eCommerce apps - it delivers a versatile, dependable, highly scalable, and cost-effective database solution for small and medium-sized e-commerce firms.
- Online and mobile apps - It enables you to create databases for large-scale web and mobile applications with scalable storage, high throughput, and high availability.
- Software as a Service (SaaS) - it allows enterprises to focus on producing high-quality applications rather than the underlying database.
Learn about our expertise in the industry and what we have to offer

Amazon RDS
Amazon RDS is one of the most widely used database services supplied by AWS that falls under relational databases. Amazon RDS is a service that supports several open-source relational database solutions, including AWS's products.
RDS is used in the cloud to set up, run, and grow a relational database. It automates administrative operations, including hardware provisioning, database configuration, backups, and more.
These database engines can be managed via a centralized administration panel, a command-line interface, or API calls. It is compatible with six prominent database engines, including Amazon Aurora, MySQL, MariaDB, PostgreSQL, Oracle, and Microsoft SQL Server, and may be used similarly.
Amazon RDS use cases are:
- For web and mobile apps: it allows the scalability, availability, and throughput required for enterprise-grade applications.
- For eCommerce applications: it provides the necessary flexibility, security, and PCI compliance for eCommerce.
- For mobile and online games: it ensures that games remain online and responsive to players by providing high throughput and availability.
Amazon Redshift
AWS Redshift is a database for extensive data analytics. It is a petabyte storage solution that is fast and entirely managed, making it simple and cost-effective to analyze all of your data using your existing business intelligence tools.
The service allows you to run complicated analytic queries on petabytes of structured data by utilizing advanced database optimization, columnar storage on high-performance local disks, and massively parallel query execution.
Amazon Redshift outperforms other data warehouses in terms of performance while remaining incredibly cost-effective. A new data warehouse may be deployed in minutes and scaled at the touch of a button.
Benefits of using Amazon Redshift:
- Queries for running in parallel across many nodes
- Data warehouses for expanding up to petabytes, getting new insights, and performing 10 times quicker than data warehouses that employ Machine Learning algorithms
- Less expensive automatic backup to Amazon S3 than competing data warehousing solutions
- Built-in security, including end-to-end encryption and firewall rules
Amazon Redshift use cases are:
- Business analytics allows running high-performance queries on petabytes of structured and semi-structured data easier and less expensive
- Predictive analytics employs SQL to develop, train automatically, and deploy Amazon SageMaker models using Redshift Machine Learning Preview to manipulate the data.
- Data as sharing function lets you share data internally and externally to safely and properly analyze operational data.
NoSQL or Key-value databases
NoSQL, or non-relational databases, disrupt the idea of storing data in tables with columns and rows, allowing for more flexible data distribution and processing.
33% of enterprises and 29% of small businesses use NoSQL databases.
It is often used to handle big data, defined as vast amounts of unstructured or semi-structured and constantly changing data.
This operates in the same way as a dictionary: the word is the key, and the definition is the value. NoSQL does not contain organized and clear tables but any information that may be delivered as a text document, audio file, or Internet publishing.
Non-relational databases, unlike most typical database systems, do not employ a tabular row and column schema. They employ a storage model tailored to the individual needs of the data stored.
When does the company need to use the NoSQL database?
- The information is unstructured or semi-structured
- The volume of data is too extensive for a relational database
- The data is a single kind and does not require the controls provided by a relational database
- There is a demand to manage the enormous amount of unstructured data, while relational databases are not appropriate for many use cases, especially those seeking very high-speed or dynamic scalability
Amazon Dynamo DB
Amazon DynamoDB is a fully managed and automated NoSQL database service supplied by Amazon. NoSQL implies you don't have to write queries to construct a table or retrieve data; instead, you can do it with a few clicks to create a dynamic database, which means you may add an unlimited number of characteristics, columns, and data.
Key-value databases are ideally suited to particular use cases, such as session data and shopping cart information, and can quickly handle read/write requests. DynamoDB can handle Serverless web applications, AWS Microservices, and mobile backends.
Benefits of using Amazon Dynamo DB:
- Simplicity to set up and manage
- Built-in security, automatic backup, restore functions, and in-memory caching
- No fees for transferring data between DynamoDB and other services in the same area
- Automatically copied data across several Availability Zones
- Key-value and document-based data models are supported
DynamoDB can manage 20 trillion requests per day and peak traffic of up to 20 million per second, which is enormous and noteworthy. Many significant firms, like Lyft, Airbnb, Redfin, and organizations like Samsung, Toyota, and Capital One, have moved their workloads to DynamoDB.
In-memory databases
Non-relational databases that rely on memory for data storage, making queries quicker by removing the need to access disks, are known as in-memory databases.
Amazon's In-memory database stores all of the data in RAM. You simply access the main memory and not any disk whenever you access the data. Because main memory is quicker than any disk, in-memory databases are quite common.
Amazon ElastiCache
ElastiCache is a fully managed in-memory data storage solution. It automates setup, hardware provisioning, configuration, monitoring, upgrades, and backup and recovery. ElastiCache allows you to scale both write and memory processes through sharing and data replication.
Amazon ElastiCache use cases are:
- Online apps and websites operate session storage
- Gaming uses leaderboards and discussion rooms
- Geospatial services provide real-time mapping and positioning
- Real-time analytics report data, including sensor processing the Internet of Things and AI applications
Document databases
A Document Database is a database that stores information using a document-oriented approach. The database engine utilizes this stored data structure to generate metadata needed for database optimization and queries.
Document databases provide flexible, semi-structured, hierarchical storage for catalogs and user profiles and content management systems like blogs, user profelies, and video platforms.
Amazon DocumentDB
Amazon DocumentDB is a fully-managed document database service. It is scalable, highly available, and MongoDB compatible. It allows you to store, index, and query JSON files. DocumentDB allows you to grow your computation and storage resources independently for optimum flexibility. It offers multi-master and multi-region capabilities, built-in encryption, automated backup and restore, and in-memory caching. It is a completely controlled, adaptable, and secure service.
Amazon Document DB applications include online publishing, point-of-sale terminals, digital archives, user preferences, authentication profiles, online transactions, and mobile and web apps.
a BPM app using JavaScript stack and Serverless on AWS
Graph databases
A Graph Store is a database representing and storing data using a graphical representation. It does not store data in tables but rather in an interconnected web-like structure that allows complicated data connections to be mapped and queried. The most used graph database use cases are:
- Fraud detection
- Social networking
- Recommendation engines
Amazon Neptune
Amazon Neptune is a managed graph storage service. It enables the storage of massive amounts of relationship data with low latency access. A graph database stores linked data with specific connections between them. It seems like a NoSQL database since there are no queries or tables, just vertices and edges. There is also a point-in-time restore, read replicas, and continuous backup.
It allows you to build and operate applications that use highly linked data sets. It allows for the storing of large collections of relationship data with low-latency access. Neptune is compatible with various graph models and languages, including RDF, SPARQL, and Gremlin.
Amazon Neptune use cases are:
- Social media networking: User profiles and content prioritization
- Data visualization graphs: Product catalogs
- Data tracing
- Engines of recommendation: store client connections, purchase history, and preferences
- Detection of fraud: overlapping email addresses, IP addresses, or credit card numbers
Time-series databases
Time-series databases are intended to store and retrieve data points that are timestamped. Time-series information is data that relates to specific points in time. They are used to integrate information across different time dimensions. Major time-series databases use cases are:
- Internet of Things (IoT) applications
- DevOps
- Industrial telemetry
Amazon Timestream
Amazon Timestream is a time-series database service that is completely managed. It is a database that does not require a server. It is also automated and completely managed.
Amazon Timestream is specialized for assessing, querying, and storing timestream data by storing data in milliseconds, microseconds, and even nanoseconds. You don't have to worry about maintenance and hardware provisioning, setup, or configuration, so you can devote more time to your business. It has an autoscaling feature, ensuring you never run out of space.
Compared to AWS's relational databases, it allows you to store, process, and analyze up to 1,000X greater query performance at 90% less cost.
Amazon Timestream has several use cases, including DevOps tools, which help performance monitoring and management, network optimization, and server monitoring for cloud build and deployment.
Ledger databases
Ledger databases have data tables and an immutable journal that tracks all data changes, generating a blockchain record of all revisions. The database runs in an always-on, highly available, and fault-tolerant environment.
The database provides strong encryption and privacy controls with robust access control lists (ACLs) and database permissions. The ledger database has multi-tenancy, guaranteeing that only authorized servers can read and write to the tables.
Ledger databases use cases are:
- Systems of record
- Supply chain
- Registrations
- Banking transactions
Amazon QLDB
Amazon QLDB is a managed Serverless ledger storage solution. It may be used to maintain a verified record of program data modifications, track application changes, and provide a verified history. It saves the record in one place, making it easier to access and work on, allowing you to focus more on evaluating and solving problems.
Still, its primary role is that it is a ledger database, which means it is used for recording or keeping an organization's financial and economic data throughout time. It enables you to save a comprehensive history of accounting and transactional data between numerous parties in an immutable, transparent, and cryptographic manner using cryptographic, making it extremely safe. Because it is serverless, the underlying hardware costs less.
AWS databases comparison
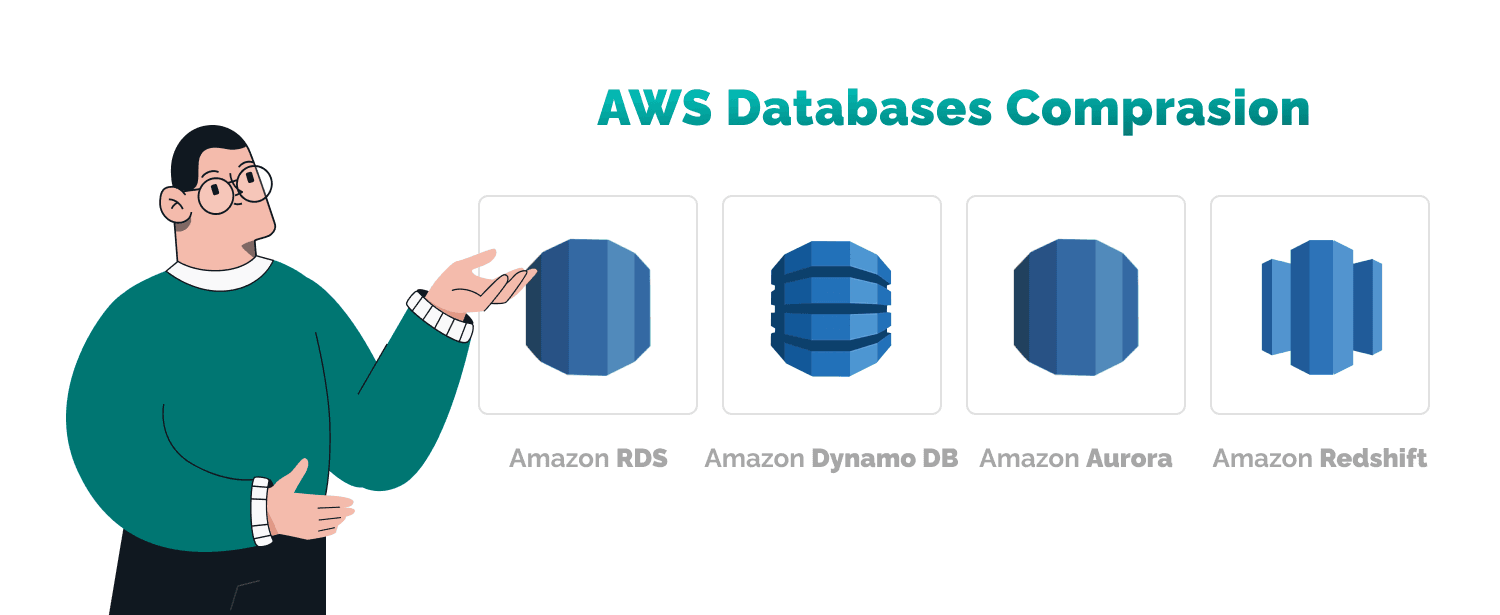
We cover only four of the most-used databases: RDS, DynamoDB, Redshift, and Aurora, to help you compare which one meets your needs.
Maintenance
- Redshift needs additional upkeep. Users are recommended to execute 'vacuuming,' which makes deleted data cells accessible for storage. It is also recommended that you check the performance of your searches. You may use AWS Console to see how long it takes for your query to run, how much CPU it consumes, and other information.
- RDS - AWS will maintain your RDS instances for the most part, with the user having the option to make some changes.
- Dynamo DB is Serverless, and the set of available and necessary settings is smaller and may not require user participation.
- Aurora's maintenance is synonymous with RDSs when used in conjunction with RDSs. There is almost little maintenance necessary while running serverless.
While all are managed database services, the intricacy of Redshift incurs some user maintenance expenses. Dynamo databases do not. Aurora may be run as a managed or serverless database with minimal upkeep.
Scaling
- Redshift architecture is more complex, scalability will be more difficult and time-consuming. Redshift can be scaled faster. At the other end of the spectrum, Redshift is the best option to handle an infinite number of queries.
- DynamoDB scales without affecting performance. Furthermore, the customer has the option of running DynamoDB in an on-demand or provisioned capacity mode where a scale restriction may be specified, similar to RDS
- RDS is easier to scale since it is less sophisticated, needing only a few clicks on the AWS Console to calculate an auto-scale max capacity. It can be run on-demand or with reserved capacity.
- Aurora scales differently depending on whether it runs on RDS or Aurora Serverless. It scales as indicated above on RDS. Aurora Serverless, on the other hand, will automatically start up, scale down, and shut down by your application's demands. However, while this sounds good, Aurora Serverless is not the most robust option, being more restricted than the majority of the other alternatives on this list.
Pricing
- DynamoDB may be charged on-demand or provisioned, but with notable differences. Users will be paid per read/write in the on-demand and supplied models.
- RDS cost depends on the engine utilized. RDS is offered as a pay-as-you-go model with a higher price or as a reserved instance model with a cheaper rate and a commitment to a set amount of usage. This includes when Aurora is operating.
- Aurora provides fast scaling and additional resiliency. When you operate serverless, you are paid by ACUs (Aurora capacity units), which equal 2GB of memory plus compute and network resources.
- Redshift offers a reserved instance and on-demand model, with extra capabilities, such as Concurrency Scaling, priced separately.
Storage
- RDS storage varies depending on the engine, although it may reach 64 TB when using Amazon Aurora. SQL supports 16 TB, but all other engines support 32TB.
- Redshift has a substantially larger maximum capacity of 2PB.
- DynamoDB has an infinite storage capacity.
AWS database migration service

AWS Database Migration Service can move data between the most popular databases. Companies use it to migrate databases across platforms or data between services. You can, for example, migrate data from EC2 to Amazon RDS or from RDS to EC2. It may also transfer data between databases, such as NoSQL, SQL, and text-based storage.
AWS Database Migration Service is free for the first six months. Only the CPU resources and log storage needed during transfer are your responsibility. All incoming data transfers are free of charge. However, engineering and log storage expenses are quite minimal. A terabyte-sized transfer, for example, may often be completed for approximately $3.
Benefits of using AWS database migration:
- Simple to deploy and control using the AWS Management tools
- Completely managed
- Maintenance databases functioning while migrating using this solution
- Less downtime for decreasing revenue loss and productivity interruptions.
Amazon Database Migration Service is robust and self-healing. However, if problems emerge, the service immediately identifies them and takes action or notifies you, resuming the migration procedure from the point where the problem occurred.
3 steps to choose the right AWS databases

When deciding on the best database for the work, businesses should estimate what usability they want from the service and select a service based on its functionality.
#1. Evaluate your needs for AWS databases:
- Based on access characteristics and/or the pattern of data being stored
- Structured, semi-structured, or segregated by size, speed, or scale
- Relational, document, graph, in-memory, or search
#2. Choose the use case that you want to cover:
- Real-time data analytics
- Million of users
- Low latency
- Transferring administration responsibilities
#3. Discover the technology stack
- Cloud architecture (Private clouds, public clouds, hybrid clouds, and multi-clouds)
- Application's data structure (Store hierarchical data, like folder structure, organization structure, XML/HTML data)
With over a dozen database engines for various purposes available, you can be confident that you'll receive good performance regardless of which engine you use. What matters most, according to Ido, is functionality. It's about the business need—whether the priority is a quick query, a fast store, or good dependability and data structure.
To sum up
The AWS database should be chosen based on technological capabilities if the project requires complicated data processing logic. Traditional SQL databases excel at managing tiny amounts of tightly typed data. A local ERP system, for example, or a cloud CRM. However, when processing a huge quantity of semi-structured and unstructured data, i.e. Big Data, in a distributed system, you should select from several NoSQL storages while keeping the task's features in mind.
When deciding on the best AWS database types for a project, it's usually a good idea to research several AWS database alternatives and get feedback from reliable AWS partners. During making this critical decision, it may become clear that the best option is a combination of databases rather than just one. Choose the appropriate database for your project's concern that works best!
If you need help determining a database based on your needs or someone to do the work for you, get a quote.
FAQs

AWS offers several relational databases, including Aurora, Redshift, and RDS, in-memory databases: ElastiCache and Dynamo DB, document databases – Document DB, and many others.
In AWS, all the databases are equal. Each database has its features and functions that can be utilized appropriately. You should test each database and select the best one for your application.
RDS, Dynamo DB, and ElastiCache are the most widespread in most projects.

